初识Kafka
开篇
在微服务的架构设计中我们一般都会考虑服务之间互相调用的问题,如何做到更好的解耦设计。在秒杀的系统中会使用异步处理的方式来设计高并发、低延迟的系统架构。提到这些相信大家都会想到使用MQ(消息队列)来处理这些问题。
MQ(消息队列) 是跨进程通信方式之一,可理解为异步RPC,上游系统对调用结果的态度往往是重要不紧急。使用消息队列有几个好处:业务解耦、流量削峰、灵活扩展
技术选型
现在业界主流的MQ有很多,比如:ActiveMQ、RabbitMQ、RocketMQ、Kafka 等,那么我们在技术选型中该怎么选择呢?
| 特性 | Kafka | ActiveMQ | RabbitMQ | RocketMQ |
|---|---|---|---|---|
| 单击吞吐量 | 10万级别,这是Kafka最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算,日志采集等场景。 | 万级,吞吐量比RocketMQ和Kafka要低一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低一个数量级 | 10万级,RocketMQ也是可以支撑高吞吐的一种MQ |
| topic数量对吞吐量的影响 | topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,Kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多机器资源。 | topic可以达到几百,几千个的级别,吞吐量会较小幅度的下降,这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic。 | ||
| 时效性 | 延迟在ms以内 | ms级 | 微妙级,这是rabbitMq的一大特点,延迟是最低的 | ms级 |
| 可用性 | 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 | 高,基于主从框架实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 |
| 消息可靠性 | 经过参数优化配置,消息可以做到0丢失 | 有较低的概率丢失数据 | 经过参数优化配置可以做到0丢失 | |
| 功能支持 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 | MQ领域的功能及其完备 | 基于erlang开发,所以并发能力很强,性能及其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 |
| 优劣势总结 | kafka的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展 同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量 而且kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略 这个特性天然适合大数据实时计算以及日志收集 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。 偶尔会有较低概率的丢失消息。 而且现在社区以及国内应用都越来越少,官方社区现在对ActiveMQ维护越来越少,几个月才发布一个版本。 而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用。 | erlang语言开发,性能及其好,延时很低:吞吐量到万级,MQ功能比较完备,而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本。在国内公司用 rabbitmq也比较多一些 但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。 而且erlang开发,国内有几个公司有实力做erlang源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复bug。 而且rabbitmq集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是erlang语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障 日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是ok的,还可以支撑大规模的topic数量,支持复杂MQ业务场景 而且一个很大的优势在于,阿里出品都是java系的,我们可以自己阅读源码,定制自己公司的MQ,可以掌控 社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准JMS规范走的有些系统要迁移需要修改大量代码 还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ挺好的 |
综上比较,可以看出RocketMQ和Kafka 优势较为明显,其实对于大多数的服务架构来说,吞吐量 和 消息可靠性 是我们选型中考虑较多的因素。接下来我们就一起来了解下Kafka 相关的内容
Kafka简介
Apache Kafka 起源于LinkedIn,后来于2011年成为Apache开源项目。Kafka是用Scala和Java编写的。
Apache Kafka官网 上介绍,Kafka是一个分布式流处理平台,具有以下三个特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似;
- 可以储存流式的记录,并且有较好的容错性;
- 可以在流式记录产生时就进行处理。
接下来我们会就第一个特性,Kafka作为消息队列所具有的优势和特点:
Kafka作为一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往消息队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
Kafka 架构总览
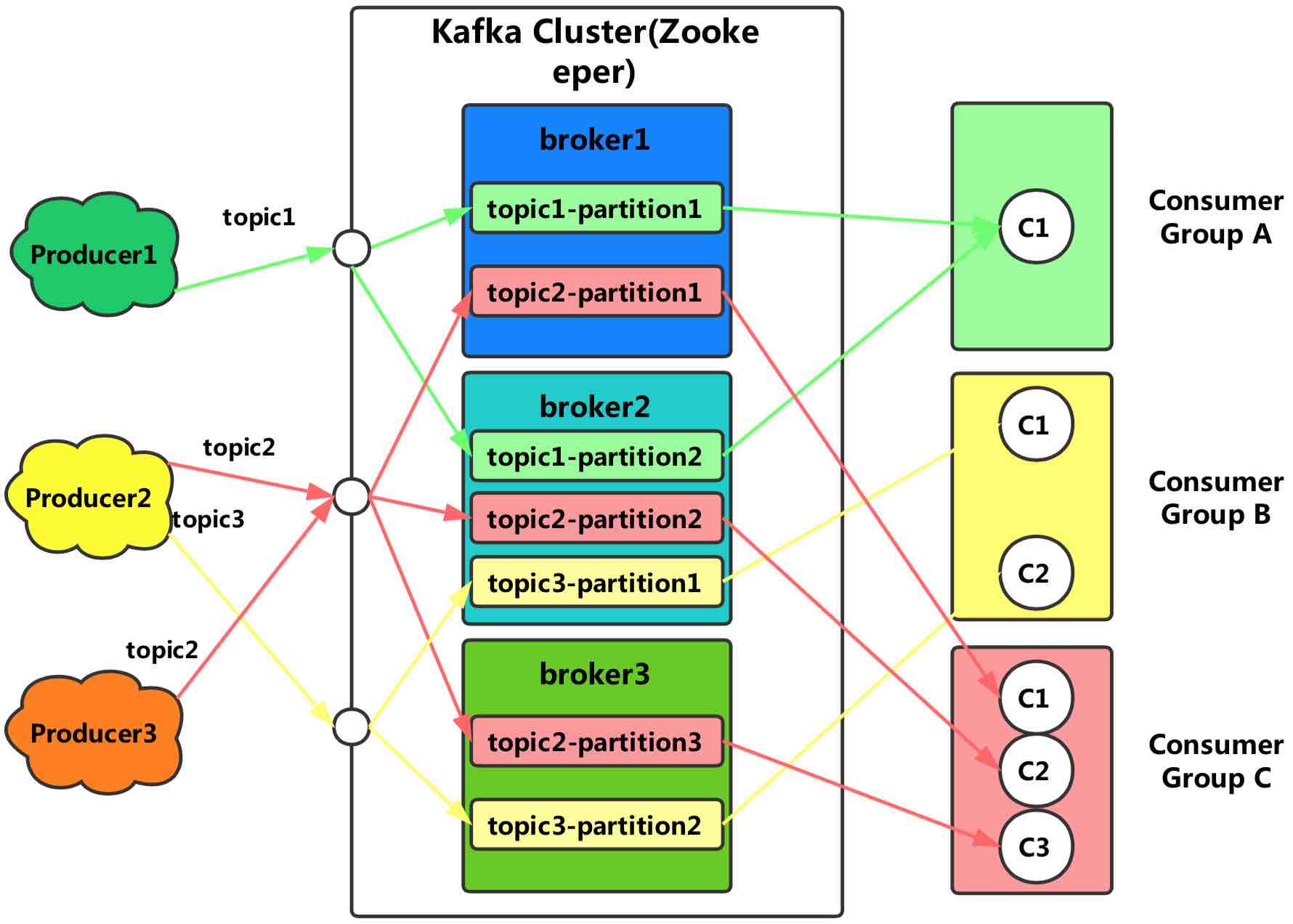
上图清晰的描述了Kafka的总体数据流,关于broker、topics、partitions 的一些元信息用zk来存
Producers负责往Brokers里面指定Topic中写消息Consumers从Brokers 中拉取指定Topics的消息,然后进行自己的业务处理
图中有3个topic:
- topic1有2个partition(topic1-partition1、topic1-partition2),两副本备份
- topic2有3个parition(topic2-partition1、topic2-partition2、topic2-partition3),三副本备份
- topic3有2个partition(topic3-partition1、topic3-partition2),两副本备份
Topic
消息的主题、队列,每一个消息都有它的topic,Kafka通过topic对消息进行归类。Kafka中可以将Topic从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,以”topicName_partitionIndex”的命名方式命名,该dir包含了这个分区的所有消息(.log)和索引文件(.index),这使得Kafka的吞吐率可以水平扩展
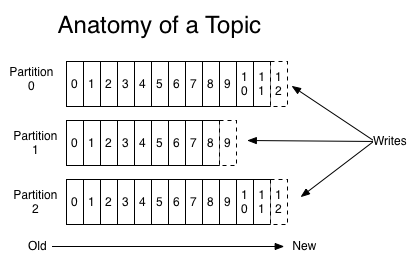
Partition
每个分区都是一个 顺序的、不可变的消息队列, 并且可以持续的添加;分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
producer在发布消息的时候,可以为每条消息指定Key,这样消息被发送到broker时,会根据分区算法把消息存储到对应的分区中(一个分区存储多个消息),如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡。
Broker
Kafka server,用来存储消息,Kafka集群中的每一个服务器都是一个Broker,消费者将从Broker拉取订阅的消息
Producer
向Kafka发送消息,生产者会根据topic分发消息。生产者也负责把消息关联到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。算法可由开发者定义。
Cousumer
Consumer实例可以是独立的进程,负责订阅和消费消息。消费者用consumerGroup来标识自己。同一个消费组可以并发地消费多个分区的消息,同一个partition也可以由多个consumerGroup并发消费,但是在consumerGroup中一个partition只能由一个consumer消费
CousumerGroup
同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer
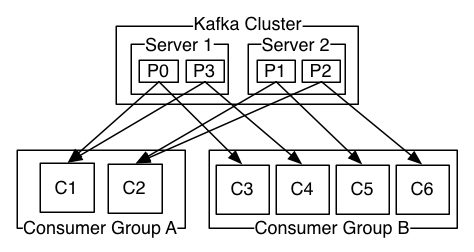
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个”逻辑订阅者”。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
Kafka配置项
http://kafka.apachecn.org/documentation.html#configuration